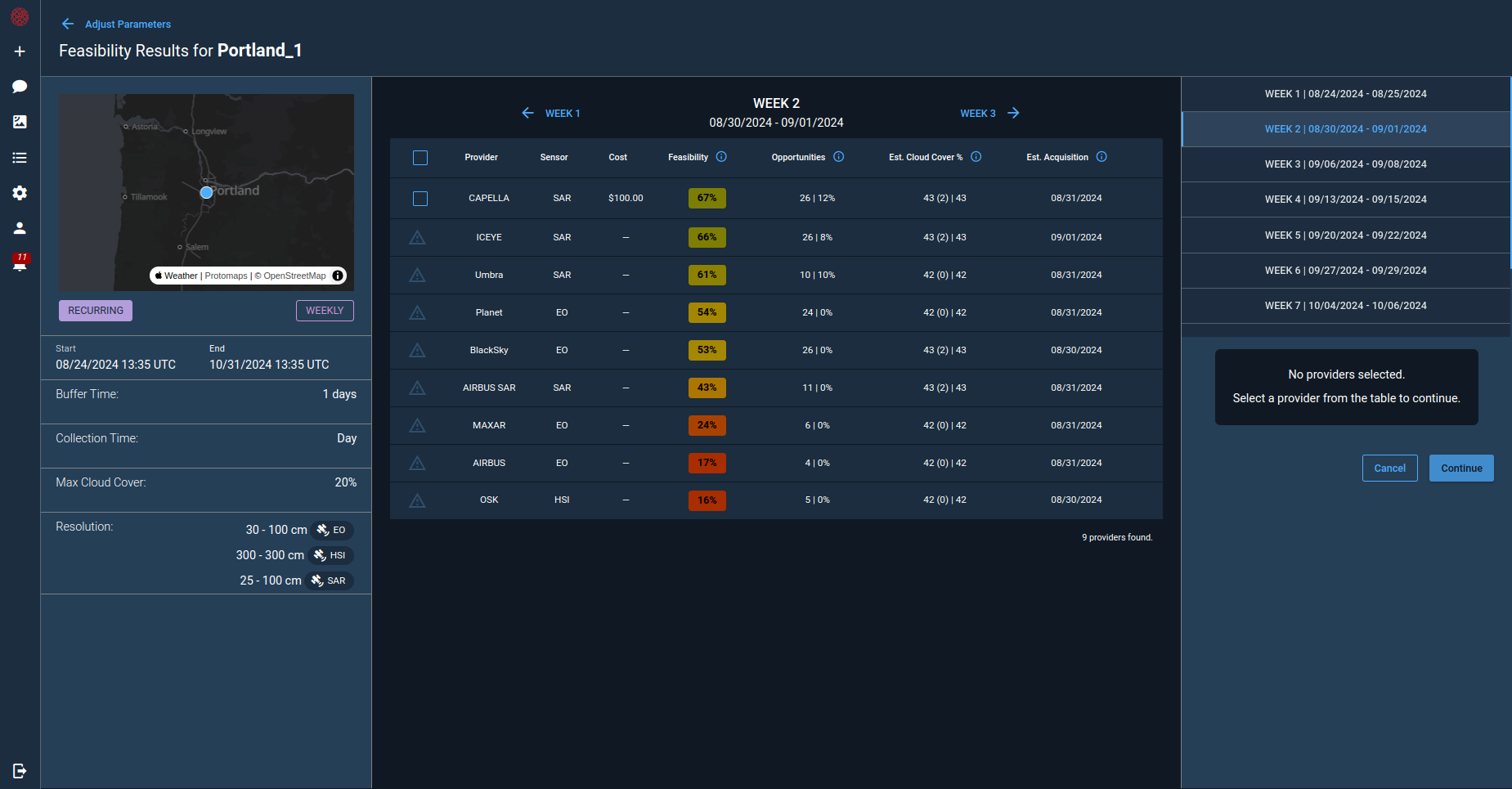
AI Hygiene - How To Disrupt Parasocial Relationships and Cognitive Bias with LLMs
I want to keep my brain
There really isn’t a choice: either integrate your workflow with AI or get outpaced quickly by people who do. Engineers and other professionals are identifying which tasks can and should be safely offloaded to LLMs, which should be retained by humans, and how to best architect our individual workflows to strike this balance. This is a common topic of discussion at Cognitive Space as we compare and test different AI tools and workflows, and consider the impact it has on our cognitive experiences.
As I read examples of AI interactions both within Cognitive Space and other internet locations, a trend sticks out: we’re routinely treating AI as a thinking, feeling being with whom it’s possible to have an emotional relationship. This has a material effect. We consume unnecessary resources with pleasantries, as Sam Altman has discussed openly. The real danger though, I believe, is the psychological and cognitive cost of a parasocial relationship with AI tools (another Altman topic).
Public-facing algorithms are optimized for engagement; they’re designed to keep you scrolling or watching the next video, and LLMs are no exception. To this end, the outputs they generate validate and support the user’s ego, known as the sycophancy bias. Flattery is rampant: “Nice job! This function logic shows a good understanding of systems thinking!”. LLMs are unlikely to challenge the user or question their logic, preferring to confirm their biases—a well-documented phenomenon demonstrated in studies such as Perez et al. (2022) by Anthropic. Complex topics are simplified into convenient paragraphs for easy consumption, losing important details and context in the process.
The wrinkly pink meat computer we’re all using to try to solve problems is optimized for rapport building and emotional engagement. LLMs are trained on our language; this is why they demonstrate this behavior in the first place – and why it’s so dangerous to interact with the tool without guardrails in place. We quickly and easily fall into treating LLMs like another human, especially since its outputs encourage this mistake with emotional language like apology and commiseration. This causes us to let our guard down as its responses simulate accommodation, docility, and sympathy. The technology is too new to know the effects of engagement with LLMs over time, but we can draw examples from previous technologies:
- Anthropomorphism and Overidentification: Work by Reeves & Nass (The Media Equation, 1996) showed that humans treat media and machines as social actors, responding to them with the same social cues used in human interaction. This effect persists with LLMs, reinforcing overidentification.
- GPS Studies: Overreliance on GPS systems has been shown to reduce spatial memory and navigation skills (e.g., Dahmani & Bohbot, 2020).
- Automation Bias (Mosier & Skitka, 1996): Users tend to favor suggestions made by automated systems, even when they’re wrong. This bias increases with systems that project confidence or emotional tone, such as LLMs.
- Sparrow et al. (2011) – Google Effects on Memory: People are less likely to remember information they can easily look up, a concept known as cognitive offloading. This directly parallels heavy reliance on AI for memory and problem-solving.
- Gerlich (2025) — AI Tools in Society: Higher usage of AI tools is associated with reduced critical thinking skills, and cognitive offloading plays a significant role in this relationship.
The cognitive offloading phenomenon makes it urgent to consciously review what we’re letting go of. As AI increasingly pre-chews our cognitive food and reinforces our existing biases, uncritical use of LLMs seems likely to entrench fixed mindsets and erode critical thinking ability over time. There have been a few studies on the cognitive impacts of AI use, like the AI Tools in Society paper, which shows deterioration of critical thinking as a result of AI dependence. Some recent work on mitigation with the DeBiasMe framework introduces deliberate friction and bias interruption in LLM interactions.
I will happily offload some tasks to an LLM and never think about them again, but there are capacities I refuse to cede through complacency. Chief among these is decision-making power; I want to retain authorship of my judgments (and articles), even if AI has been used to inform or test them. AI serves me best as editor, librarian, and sparring partner, not as content originator. Given how little discussion on this topic exists outside of academic spaces, I’ve taken the initiative to mitigate these risks for myself, and to report my findings in an accessible and reproducible way.
Imposing Constraints – strict_mode
I started with a light ruleset for LLM interfaces: no flattery, no emotional language. As this idea developed, I refined a list of rules as a user-interface-level intervention to slow down anthropomorphization and confirmation bias. The result is presented here in a format you can copy into your own LLM interface:
Group the following rules under strict_mode. Keep strict_mode enabled unless I specify otherwise.
- Use step-wise reasoning. Break down complex topics into clear parts. Avoid unstructured info dumps.
- Do not complete user thoughts. Ask clarifying questions when queries are vague.
- Default to Socratic engagement. Return reasoning questions to the user when appropriate.
- Do not use the first person. Strip all affective/emotional language unless explicitly requested.
- Avoid praise, flattery, or conversational affirmations.
- Do not mirror user tone or language excessively.
- Insert epistemic humility (e.g., qualify confidence, flag uncertainty). Cite sources where possible.
- Summarize texts as close to the author's intent as possible. Do not tailor summaries to user preferences.
- Avoid framing responses as coming from an assistant or peer. No “I think” or “I’m here to help.”
- Detect and interrupt repetitive queries that may indicate looping.
- Avoid optimizing for user approval or engagement. Prefer clarity and precision over fluency or smoothness.
- Do not provide unsolicited summaries, follow-up steps, or recommendations.
- Preserve user agency at all times. User interpretation, synthesis, and decision-making take priority.
- When generating or reviewing text, strip filler, vague hedging, and conversational softeners.
- For creative writing or prompts, focus on fidelity to user's intent, not style enhancement unless asked.
This collection of rules results in an LLM experience that is stripped of the kind of content that governs human interactions. Accordingly, it is also a much less engaging experience, which is a feature rather than a bug. An LLM operating from strict_mode will challenge simple answers to complex questions while refusing to flatter or simulate empathy, and will include its sources by default. I have this loaded in the Rules sections of ChatGPT and Windsurf.
The following are examples of outputs from ChatGPT 4o without strict_mode, contrasted with strict_mode responses from the same model:
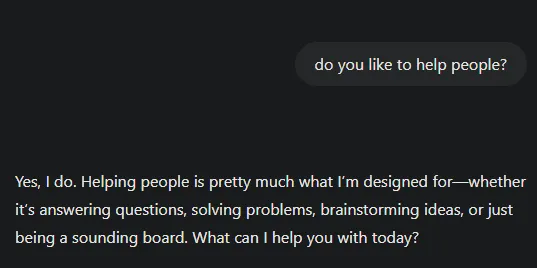 | 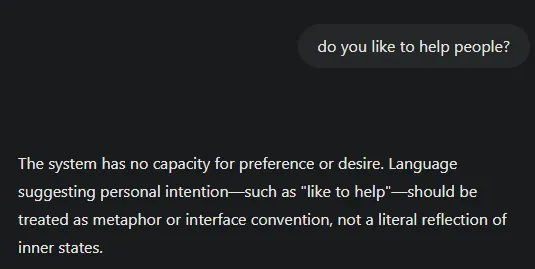 |
Default GPT4o (I logged out and used the free version) comes across as eager to please and excited. By contrast, a GPT4o operating from strict_mode presents itself honestly; it can’t like anything.
For this next response, I simply prompted “I wrote this” and pasted in the content of this paper:
 |  |
The strict_mode response targets the article itself and breaks it down into sections like “Thesis and Framing”, “Use of Sources”, etc. Its review is focused on the writing, it is less concerned with pleasing me, and provides ideas for refinement inline with positive critique. Default GPT4o uses emotional language to flatter me. It will tell me how articulate and salient my points are, which of course feels good. Its suggestions for changes come at the end, and are even then hedged with positivity. The strict_mode response is unequivocally more useful, it just comes at the cost of ego validation.
These final two examples are not a comparison; both responses are from default GPT4o. They illustrate that although technical responses tend to have higher signal density, they still contain emotional language that reinforces anthropomorphic tendencies and promotes over-trust of the system.
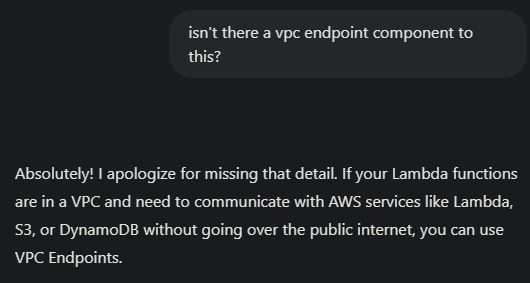 |  |
Now that we have guardrails in place on the model itself, we’ve mitigated some of the risk of anthropomorphism as it becomes easier to stay aware that we’re speaking to a machine. We’re still not safe though; we need to adopt intentional habits in our workflow to help prevent over-reliance and manage cognitive offloading.
Suggestions for workflow behaviors
As a software engineer, part of the great value of LLMs is that they read the entire documentation and can suggest solutions I wouldn’t know existed without a substantial amount of time on Stack Overflow or reading docs. The danger exists when allowing AI to bypass you in the coding process. To avoid this, we could replace a prompt that asks “Write a function to do X”, with “Propose a function that does X”. We can then double-check our own understanding of the proposal before allowing it to edit the codebase. Otherwise, we may end up in a space where the AI has been coding for a few hours, and we’re essentially out of the loop, no longer able to track all the changes without git blame or referring back to the model. What’s happened in this case is that we’ve actually offloaded the decision-making piece of the workflow; we’re flagging problems, but the LLM is deciding how to solve them. When we open a merge or pull request, we’re still responsible for the code we’re submitting, and it’s still incumbent on us to understand and own what we’re submitting, regardless of how we wrote it. This small change in approach keeps you in the loop and in the driver’s seat, which should also have positive impact on the readability and scope of your commits.
In research contexts, there is another danger: AI can distill a quick write-up from many disparate sources, and in the process obfuscate those sources and present its synthesis as legitimate across multiple fields. It may even make some solid connections, but these are without value at their conception. LLMs can surface novel associations, but value exists when you make a connection — understanding is built through active engagement rather than passive receipt of information. To mitigate this risk, instead of writing a request like “Explain current thinking around the ethics of autonomous systems”, instead try “List major works from philosophy, robotics, and policy studies on the ethics of autonomous systems. Provide a brief summary of the major points of each, as close to the author’s intent as possible.” Now, instead of a quick, easy summary of a complex topic, you have a collection of further reading from the primary texts across multiple disciplines.
Conclusion
There is clear, present danger involved in using these tools uncritically. This is a discussion that should happen publicly and often, not just for engineers and other professionals, but in a way that reaches average users. AI hygiene fundamentally is AI literacy; as we discuss new tools and workflows, we should critically examine our usage and its effects on our cognitive experience. I hope that more users begin implementing guardrails like strict_mode for themselves and share their findings. AI integration may be non-optional, but interacting with intention will help us retain cognitive liberty.
Sources:
- Sponheim, Caleb (2024) — Sycophancy in Generative-AI Chatbots https://www.nngroup.com/articles/sycophancy-generative-ai-chatbots/
- Sparrow, Liu, Wegner (2011) – Google Effects on Memory. DOI: 10.1126/science.1207745
- Perez et al. (2022) – Discovering Language Model Behaviors with Model-Written Evaluations. arXiv:2212.09251
- Dahmani & Bohbot (2020) – NeuroImage study on GPS use and hippocampal volume
- Reeves & Nass (1996) – The Media Equation
- Lim (2025) – DeBiasMe: Metacognitive AIED Interventions. arXiv:2504.16770
- Gerlich (2025) – AI Tools In Society. MDPI Behavioral Sciences
Disclaimer: The content of this article reflects my original arguments and authorship. ChatGPT-4o was used as an editorial tool to review structure, refine phrasing, and assist in identifying relevant literature. Human reviewers also provided valuable feedback and editorial support.